体系结构概述¶
本文描述了Scrapy的体系结构及其组件如何交互。
概述¶
下图显示了Scrapy架构及其组件的概述,以及系统内部发生的数据流的概要(以红色箭头显示)。下面提供了这些组件的简要说明以及有关它们的详细信息的链接。数据流也描述如下。
数据流¶
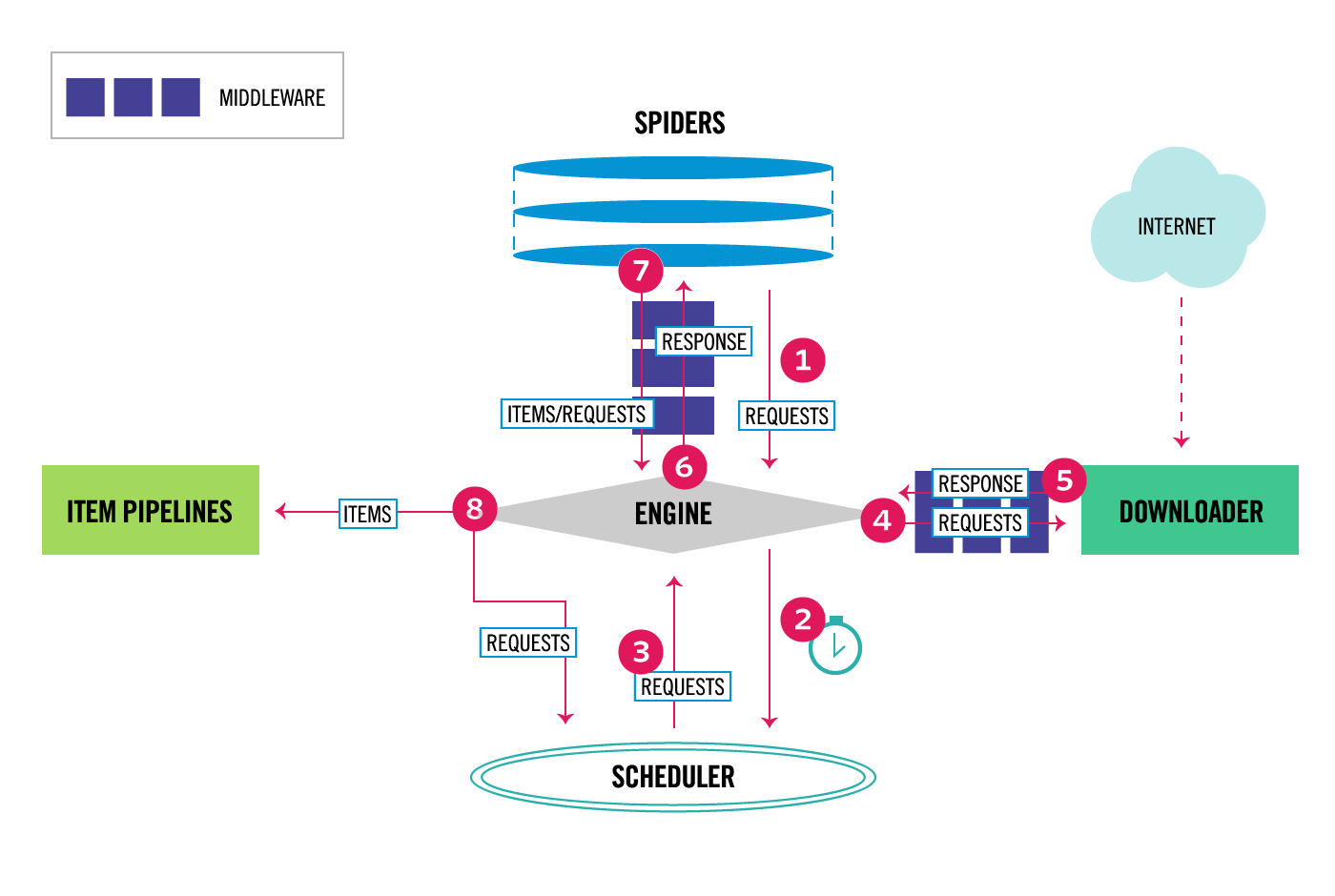
Scrapy中的数据流由执行引擎控制,如下所示:
这个 Engine 将请求发送到 Downloader ,通过 Downloader Middlewares (见
process_request())一旦页面完成下载, Downloader 生成响应(使用该页)并将其发送到引擎,并通过 Downloader Middlewares (见
process_response())这个 Engine 接收来自的响应 Downloader 并发送到 Spider 用于处理,通过 Spider Middleware (见
process_spider_input())这个 Spider 处理响应并向 Engine ,通过 Spider Middleware (见
process_spider_output())这个 Engine 将已处理的项目发送到 Item Pipelines ,然后将已处理的请求发送到 Scheduler 并请求可能的下一个爬行请求。
该过程重复(从步骤1开始),直到不再有来自 Scheduler .
组件¶
下载器¶
下载者负责获取网页并将其送入引擎,引擎反过来又将网页送入蜘蛛。